
By: Anna Muszkiewicz, Senior Data Scientist
At Tala, we use novel machine-learning approaches to provide access to credit for the Global Majority. We serve our customers best by continuously unlocking new, better ways to deliver credit.
The data science team is a driving force behind Tala’s rapid innovation. To ensure we can innovate without being slowed down by maintenance of existing pipelines, we have incorporated software development best practices into our data science workflow seamlessly for our team. As a result, our data scientists create and maintain production-ready ML pipelines with minimal overhead. With a single command, we set up automated testing and deployments via CI/CD workflows. This safeguards our pipelines from degradation, enables routine model re-training with new data to improve model performance, and allows us to focus on novel research and innovation.
Here’s how we arrived at this data-science-friendly solution for integrating software development best practices into our data science workflow.
Seamless CI/CD workflows for data scientists
We are using continuous integration and continuous delivery/ deployment because they help us ensure a seamless customer experience and allow us to deliver a robust customer journey.
To promote reusability and shorten development cycles, we share code where possible. This leads to an old software development problem: how do we safeguard against software regressions, or situations where previously-working code stops working? A standard way of preventing regressions is to use automated tests, so that’s what we set out to do.
Our ML training pipelines are developed by data scientists; therefore, tests should complement our development process. Our requirements are:
- The testing framework should meet software development rigor while being data-science-friendly, allowing data scientists to use CI/CD workflows without having to debug them or write them from scratch.
- During development, we want to have flexibility to run the tests locally and on a Kubernetes cluster. This is to ensure that the pipelines can run successfully in production.
- By design, our training pipelines follow a “configuration as code” approach to support scalability across markets. In a similar fashion, we expect to easily toggle between markets when running tests.
Our setup
We build our batch ML training and inference pipelines using the following tools:
- A proprietary feature store solution to ensure consistent feature definitions across pipelines, as well as between model training and serving
- Industry-standard ML and AI libraries
- GitHub Actions CI/CD workflows to automatically run tests on relevant pull requests
- A custom Python tool to generate CI/CD workflow files that uses a single command to create GitHub Actions workflows, requirement files, and Dockerfiles
- Custom docker images to ensure the environment is the same during model development and full-scale model training
Our solution
CI/CD jobs flag and prevent incoming regressions
The goal of tests is to safeguard against software regressions. For every model in production or close to deployment, tests are automatically triggered on relevant pull requests as part of the CI/CD workflow for each pipeline. The tests run in parallel across multiple pipelines simultaneously. For any single pipeline, the tests also run in parallel across markets. We have the flexibility to choose whether to run the tests locally (on a GitHub runner) or on a Kubernetes cluster.
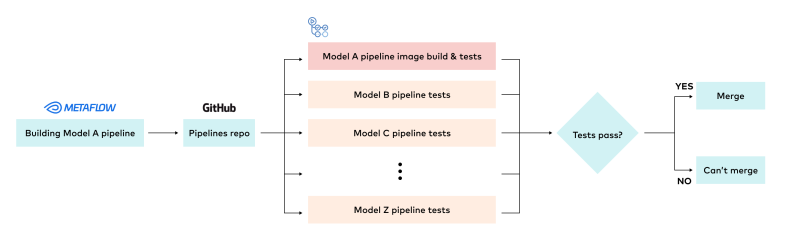
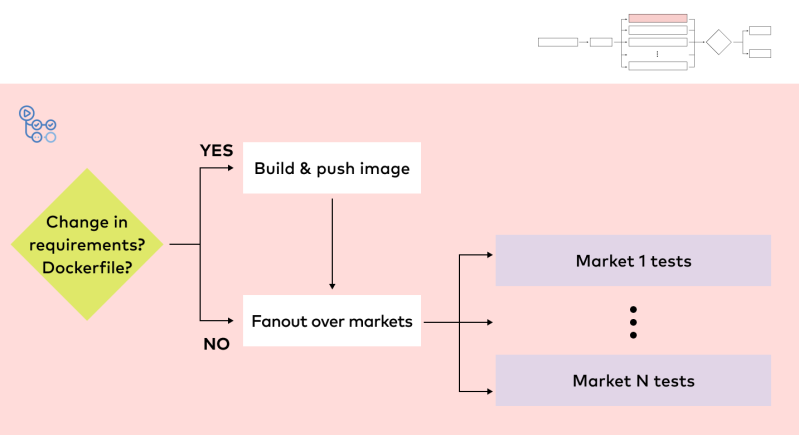
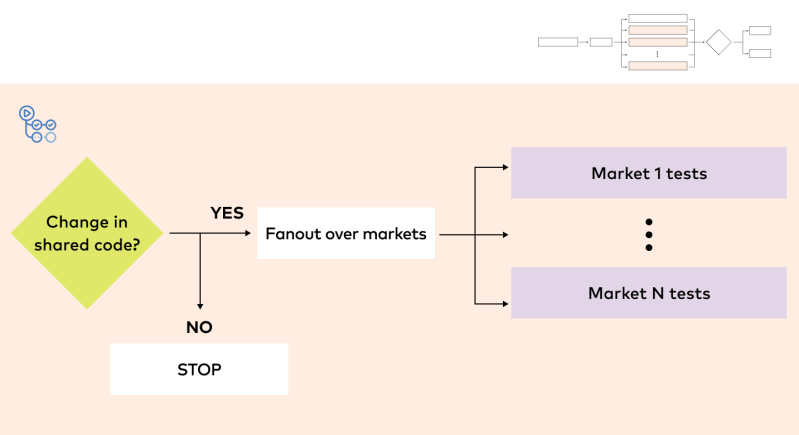
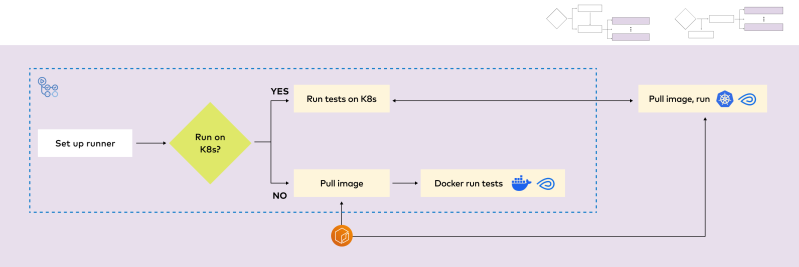
We use custom Docker images to ensure the environment is the same during both model development and full-scale model training. To test the pipeline for a corresponding model that is already in production, the pre-built Docker image is retrieved for testing purposes during the CI/CD workflow. For a pipeline under active development, the Docker image is built as part of the CI/CD job itself. Once built, the image is then retrieved and used for both testing and full-scale training in the future.
What we do (and don’t) test
At Tala, our libraries and proprietary feature store are already extensively tested, so we don’t test them here. When writing tests for our batch training/inference pipelines, we prioritize coverage and reproducibility. The tests that data scientists write during pipeline development include:
- Integration tests to ensure that pipelines run successfully in 10 minutes or less, using a minimal dataset, a low number of iterations, and a small set of hyperparameters.
- Tests safeguarding against software regressions. For this purpose, a small and fixed dataset can be used to train a model predicting close to random. The test asserts that model predictions match expected values.
- Anything that a data scientist deems important. For instance, while refactoring an older pipeline, a test asserting that the new pipeline generates the same predictions is useful.
How this enhances the work of data scientists
From a data scientist’s perspective, writing tests and having them triggered on relevant pull requests ensures existing pipelines don’t break, and model re-training is truly a push-button exercise. Reducing toil frees up time for innovation, and ensures our customers continue to get the products and services they need to manage their financial lives.
Integrating software engineering best practices into a data scientist’s workflow has other advantages. Contrary to popular belief, testing doesn’t prolong development time, but rather accelerates it by ensuring a set of passing tests regardless of code or dependency changes.
To facilitate adoption of best practices on our team, we have implemented regular pairing sessions and provided guidance and resources, including documentation and video recordings. Data scientists at Tala have also adopted a “deliver then iterate” approach, writing the end-to-end pipeline with rudimentary data ingestion, model training and evaluation elements, and only then refining the individual components. This iterative approach permits us to uncover and address any would-be blockers early in the model development life cycle.
Equally important, data scientists are not expected to become engineering experts. This is why we have automated the generation of GitHub Actions workflows, requirements files, and Dockerfiles. The intention is that data scientists rarely have to look under the hood to debug these. As a result, sporadic support from a single machine learning engineer is sufficient to keep the process going.
Data scientists leverage ML engineering excellence to drive innovation
By integrating software development best practices into the data science workflow, data scientists at Tala can maximize time spent on innovation and rapidly bring proven, novel ideas to market. Data scientists build and maintain production-ready ML pipelines, write automated tests, and create CI/CD workflows that trigger on relevant pull requests. This safeguards our codebase from software regressions. As a result, ML batch training and inference pipelines are tested and testable. This allows data scientists to focus on innovation, and ultimately enables Tala to relentlessly focus on serving our customers better and better, every day.