By: Will High, Senior Director, Data Science
Data science is at the heart of Tala. Our combination of a data moat and state-of-the-art AI tooling enables us to offer credit to the underbanked in dynamic regulatory environments without necessarily relying on credit scores. A key market advantage is the ability to continuously innovate predictive and causal credit, fraud, and recovery machine learning models with the promise of lifting customer lifetime value and expanding financial inclusion. But gains from research efforts go unrealized unless the ML model time-to-market is equally agile.
We are thrilled to announce that Tala has entered into its new era of continuous ML model delivery. This marks a significant leap forward in efficiency, responsiveness, and overall performance that ensures Tala will maintain its leading position as a credit product innovator for the global majority.
This year, we rebuilt our batch model training, real-time feature and model serving, and acceptance testing infrastructure from the ground up to address our biggest pain points and make progress toward push-button automation. As we have rolled out the changes this month, we are seeing dramatic, double-digit lifts in speed and efficiency with historically low risk-event exposure. Less time wrangling machine learning code and infrastructure translates directly into more time improving models and building new ones to drive compounding business impact and, ultimately, value to our customers.
Streamlining deployment to enable continuous innovation
We focused on three areas of improvement to minimize manual toil for our developers and data scientists and to address bottlenecks in our model development lifecycle.
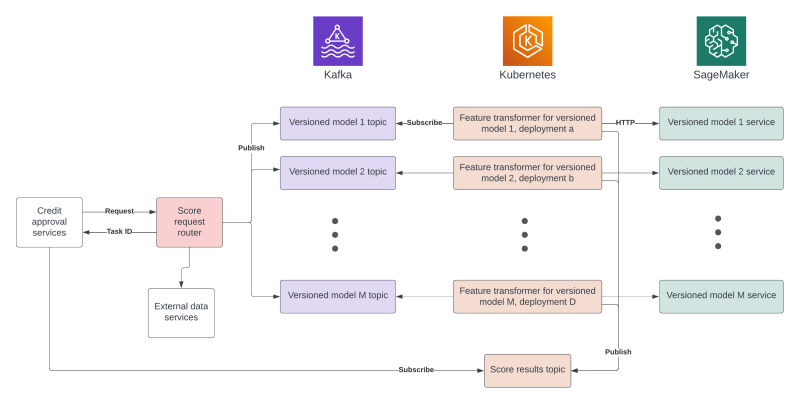
- Streamlined feature service deployments using a simple architecture that prioritizes automation, observability, debuggability, durability, and fast canary deployments using Flask, Kubernetes, and Kafka.
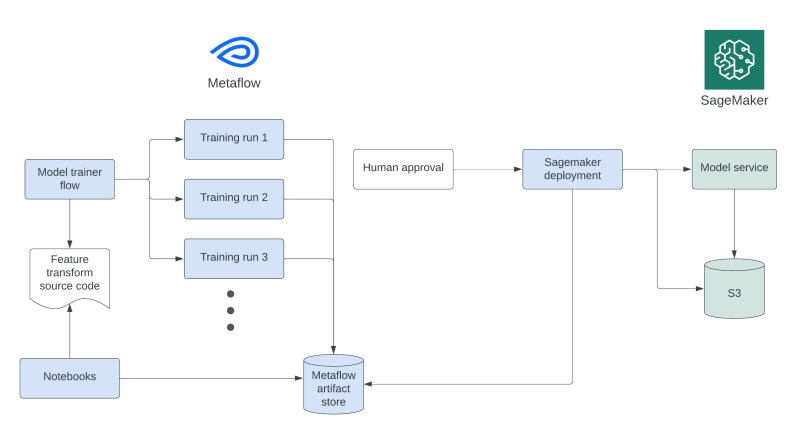
- Reproducible and scalable model trainers using Metaflow from Outerbounds that allow data scientists to own production-worthy, push-button model training code.
- Automation and self-service at all opportunities.
Reduced model training time
Under the new infrastructure, keeping models fresh and compliant is light work. In just a day or two we are able to:
- remove model features that become unavailable
- add already acceptance-tested new model features
- refresh the model by simply training on newer data
We achieve speed and reliability by leveraging cached, precomputed features and adopting Metaflow to run model training jobs with horizontal parallelism. Metaflow also yields us a 5x boost in cost efficiency over our previous practices because it uses shared compute resources on demand instead of data scientists using dedicated, always-on computers.
Blazingly fast onboarding
Our new designs also significantly decrease the time it takes to initiate a training run in production for data scientists rotating across models and for new data scientists joining the team. By eliminating cross-team requests, leaning into self-service and automation, and prioritizing trainer durability, the time-to-trigger for these training runs is now just minutes. Putting it all together, total time for a new hire to train their first model has gone from multiple weeks or months to about a day.
Sub-second credit scoring
Median scoring time for new borrowers has also sped up, primarily due to simplifying the ML architecture. We see sub-second typical feature generation and model scoring latency. End-to-end credit approval decisions for Tala customers, from application submission to decision, now take less than three seconds – a sizable improvement over our previous architecture.
Stack modernization
We modernized the stack, including leveraging canary deployments in Kubernetes that autoscale up and auto-rollback when errors are detected, and we optimized bottlenecks in our deployment pipelines. Previously, our deployments were time-intensive and occasionally required painful manual reversions. Deployments now take less than two hours, and reversions are automated and fast to dramatically minimize exposure to our customers. While there is still room for improvement, these deployment times are substantially faster than before. Production hotfix time is now less than ten minutes, and feature service rollback is essentially instantaneous when we need it.
Strategic scalability: Configurable solutions for Tala’s growth
Each of these solutions is scalable to all current and future Tala markets primarily via configuration changes and shared code. This means we can speedily enter new markets with low variable costs, which is no small feat. While US lending hinges on making marginal improvements to FICO scores in a single market, bureau data within our multiple markets — if available at all — is inconsistent and does not cover the huge populations we at Tala are specifically trying to serve. Our ability to sustainably provide the global majority with access to credit hinges on ingesting novel data types and quickly incorporating them into our core ML models. Doing this, especially under varied and changing regulatory environments, requires a high level of agility. This is Tala’s differentiating core competency and a top priority when improving the ML infrastructure.
These improvements are a testament to our pursuit of efficiency and excellence. It is progress with compounding benefits. We’ve increased our data scientists’ research and analysis time to upwards of 70% as they reduce time spent wrangling code and infrastructure, and our machine learning engineers can operate an ML infrastructure that they feel deeply invested in and can be extremely proud of, and that enables Tala to unlock the power of data to drive value for our customers.